Set enumeration trees (SE-trees) can be very useful in machine learning and data mining applications. We'll begin to cover some of the basics of these trees today, and go into more detail about their structure, traversal, and uses later.
1. Background
Binary trees were first proposed in the 1950’s as a search
methodology to locate one piece of data from within a large dataset quickly and
efficiently. During the 1960’s formal
proofs were developed to substantiate theorems and algorithms associated with
these search trees. The 1970’s brought
forth a proliferation of various mutated tree types to solve unique search
problems associated with more complex data structures. Within this same period of time trees, along
with lists, stacks, and queues, became the basic data structure building blocks
of the rapidly growing computer science field.
After several false starts, the 1980’s saw resurgence in the field of
artificial intelligence. Data mining
began to take shape and evolve with the advent of decision trees.
In 1990 a formal definition was developed for a unary
predicate set operator which produced what was termed an enumerated set (Trybulec 1990) . This enumerated set was also known as a power
set P(A) of set A in the
domain of mathematics. In 1992 a tree
structure was proposed based upon this enumerated set. This structure was named the set enumeration tree, or SE-tree (Rymon 1992). The SE-tree, or one of its fundamental
equivalents (i.e. lexicographic tree, search space lattice, prefix tree, trie),
has become the standard for search itemset identification in the field of
associative rule mining since its introduction.
If a set was composed of the elements {1,2,3,4},
then the resulting enumerated set would be as shown in Figure 1.
Figure 1
Enumerated set for
{1,2,3,4}
2.
Implementation
2.1.
Tree
Structure
There are two features that must be implemented in a general
tree structure which will be used to form a set enumerated tree. These features differentiate the general tree
from a binary search tree structure.
First, any parent node must be able to accommodate k number of child nodes (siblings).
A binary search tree has at most two child nodes for each parent
node. Second, any node must be able to
represent a set of data containing m
number of elements. A binary search tree
holds only one data element per node, with each element placed in a particular position
(or ordered) within the binary search tree depending on the element’s value.
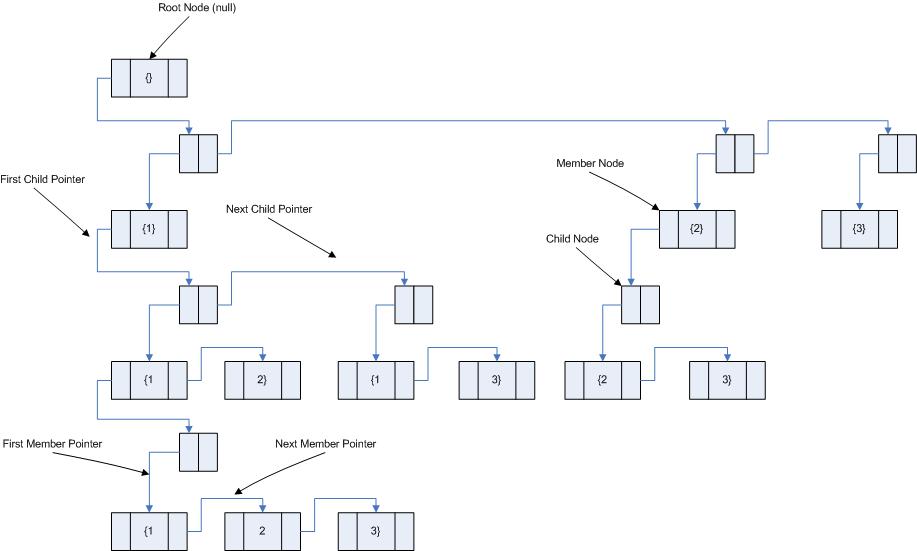
Figure 2 represents the conceptual model of a general tree
structure which satisfies the requirements for a set enumerated tree of the set
{1,2,3}.
The root node of a set
enumerated tree is always a null value, or empty set. The tree consists of two node types. The first node is the member node, which contains the actual set member values (the
braces are not included in any of the member nodes; they are just in the
diagrams to help define where a particular set begins and ends). If there is more than one member in a
particular set, then member nodes can be linked together through the next member pointer to represent each
additional set member. The second node
type is a child node. If a member node set has any child sets, then
the first member node of the parent set will be linked to a child node through
the first child pointer. The child node then will be linked to the
first member of the child set of data through the first member pointer. If a
parent set has more than one child set, additional child nodes can be linked
together through the next child pointer
for each additional child set.
Figure 2 Tree structure
for enumerated set {1,2,3}
2.2.
Node Structure
In order to simplify data structures and recursive
algorithms, it was decided to define a universal node structure which would
satisfy the needs of both a member node structure and a child node
structure. A block diagram of this
universal node structure is shown in Figure
3. The role of
the universal node structure is determined by the state of isChildNode. If isChildNode
is set to true, the universal node represents a child node. Conversely, if isChildNode is false, the universal node
represents a member node.
Figure 3
Universal Node Structure
When configured as a member node, the active variables of
the universal node structure are member,
level, *firstChild, and *nextMember. The member
variable contains the actual member value at this particular location within a
set. The level variable holds the depth within the set enumeration tree at
which this set member resides. This
variable and its usefulness will be discussed in more detail later. The *firstChild
variable is a pointer type which references the location of the first child
node if this member node has any children.
If this member node has no children (a leaf node), then the value of *firstChild is null. The *nextMember
variable is a pointer type which references the location of the next member of
a set, if one exists. If this member
node is the last or only member of the set, then the value of *nextMember is null.
When configured as a child node, the active variables of the
universal node structure are *firstMember,
and *nextChild. The *firstMember
variable is a pointer type which references the location of the first member
node of the set associated with this child node. The *nextChild
variable is a pointer type which references the location of the next child node,
if one exists. If this child node is the
last or only child set, then the value of *nextChild
is null.
2.3 Code Structure
2.3.1 Universal Node Structure Class:
typedef
int setType; //configure type of set here
class universalNode
{
public:
universalNode(void);
~universalNode(void);
private:
setType
member;
bool
isChildNode;
int level;
universalNode * firstChild;
universalNode * nextMember;
universalNode * firstMember;
universalNode * nextChild;
// for a doubly-linked structure, uncomment
the following items:
//universalNode *
backMemberFromMember;
//universalNode *
backChildFromMember;
//universalNode *
backMemberFromChild;
//universalNode *
backChildFromChild;
friend class SETree;
};
2.3.1 Universal Node Constructor:
universalNode::universalNode(void)
{
member = NULL;
level = 0;
isChildNode = false;
firstChild = NULL;
nextMember = NULL;
firstMember = NULL;
nextChild = NULL;
// for a doubly-linked structure, uncomment
the following items:
//backMemberFromMember
= NULL;
//backChildFromMember
= NULL;
//backMemberFromChild
= NULL;
//backChildFromChild
= NULL;
}
2.3.1 Set Enumeration Interface:
typedef int * arrayPtr;
class SETree
{
public:
SETree(void);
~SETree(void);
SETree(const
setType memberList[],const int size);
universalNode * buildTree(const setType memberList[],const
int size);
int
getLevelCount(universalNode *& setPtr);
int
getNodeCount(universalNode *& setPrt);
arrayPtr * getSearchArray(universalNode
*& setPtr, int & arrayDepth, int & arrayWidth);
arrayPtr *
getReverseSearchArray(universalNode *& setPtr, int
& arrayDepth, int & arrayWidth);
arrayPtr *
getLevelSearchArray(universalNode *& setPtr, const
int level, int
& arrayDepth, int & arrayWidth);
private:
universalNode *head;
universalNode *child;
void
addMember(universalNode *setPtr, const setType
newMember, int & currentLevel);
void
addNewChildSet(universalNode *setPtr,const
setType newMember, int & currentLevel);
universalNode *copySet(universalNode
*setPtr, universalNode *& lastPtr, int
& currentLevel);
int
traverseChildren(universalNode *setPtr);
void
getLevels(universalNode *setPtr);
void
getNodes(universalNode *setPtr);
void
searchTraverse(universalNode *setPtr, arrayPtr * searchArray, int searchLevel, int
& arrayCount);
void
searchCopy(universalNode *setPtr, arrayPtr * searchArray, int & arrayCount);
int
nCombinationR(int n, int
r);
int
factorial(int n);
int levels;
int nodes;
int
maxSize;
};
References:
Rymon, R. (1992). Search through
systematic set enumeration. Proceedings of the International Conference on
Principles of Knowledge Representation and Reasoning, Cambridge, MA, Morgan
Kauffman.
Trybulec, A. (1990). "Enumerated sets." Formalized
Mathematics Volume 1(1): 25--34.